In early June 2023, Apple researchers unveiled a significant study that scrutinizes the capabilities of simulated reasoning (SR) models, including popular AI systems like OpenAI's o1 and o3, DeepSeek-R1, and Claude 3.7 Sonnet Thinking. The research suggests that these models tend to generate outputs that align closely with the patterns found in their training data, particularly when confronted with new problems necessitating systematic thinking. This conclusion echoes findings from a recent study by the United States of America Mathematical Olympiad (USAMO), which indicated that these models scored poorly on novel mathematical proofs.
The Apple study, titled The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity, was spearheaded by a team led by Parshin Shojaee and Iman Mirzadeh, with contributions from Keivan Alizadeh, Maxwell Horton, Samy Bengio, and Mehrdad Farajtabar. The researchers focused on what they termed large reasoning models (LRMs), which strive to mimic logical reasoning through a process called chain-of-thought reasoning. This method supposedly aids in solving problems in a step-by-step manner.
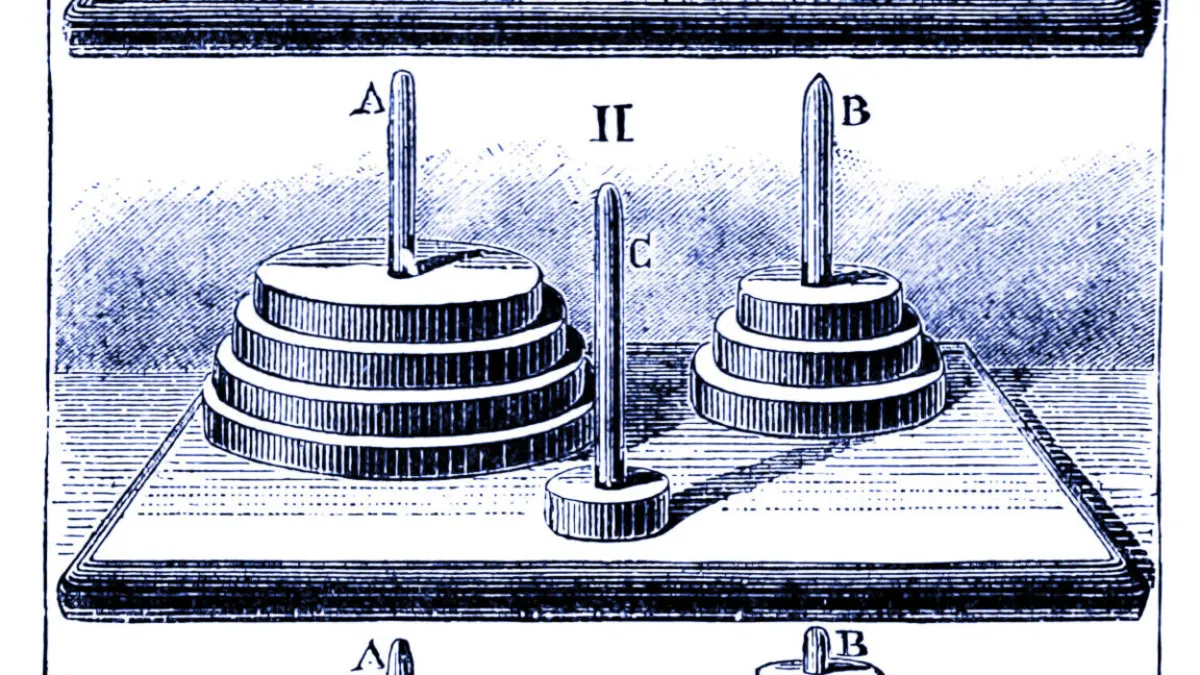
To investigate the effectiveness of these models, the team tested them against four classic puzzles: the Tower of Hanoi (moving disks between pegs), checkers jumping (eliminating pieces), river crossing (transporting items with constraints), and blocks world (stacking blocks). They varied the complexity of these tasks, scaling from trivially easy scenarios to extremely challenging ones, such as a 20-disk Tower of Hanoi puzzle that requires over a million moves.
The researchers noted that current evaluations primarily hone in on established mathematical and coding benchmarks, placing heavy emphasis on the accuracy of final answers. They argue that existing tests primarily check whether models provide correct answers to problems that may be included in their training data, neglecting to assess whether these models genuinely reasoned through the solutions or merely matched patterns from previously encountered examples.
Ultimately, the study's findings align with the USAMO research, revealing that these models garnered scores predominantly below 5 percent on novel mathematical proofs, with only one model achieving a 25 percent success rate and no perfect proofs among nearly 200 attempts. Both research teams observed significant performance degradation on problems necessitating extended systematic reasoning.
Gary Marcus, a known skeptic of AI, described the Apple results as "pretty devastating" for large language models (LLMs). He highlighted the embarrassment of LLMs struggling with simple puzzles that were solved by AI pioneer Herb Simon back in 1957. Despite providing explicit algorithms for solving the Tower of Hanoi, the models' performance did not improve, which Iman Mirzadeh, the study's co-lead, interprets as evidence that these models lack genuine logical intelligence.
The study also illustrated that simulated reasoning models behave differently from standard models like GPT-4o depending on puzzle difficulty. In simpler tasks, standard models often outperformed reasoning models due to the latter's tendency to overthink, leading to convoluted chains of thought that produced incorrect answers. In moderately difficult tasks, SR models displayed an advantage, but both types struggled significantly with complex challenges, failing to complete puzzles regardless of the time allowed.
Interestingly, the research identified a counterintuitive scaling limit. As problems became more complex, simulated reasoning models initially generated more "thinking tokens" but eventually reduced their reasoning effort beyond a certain threshold, despite having sufficient computational resources. This inconsistency in model performance raised questions about whether failures were task-specific rather than purely computational.
While some researchers argue that the study's results reveal fundamental reasoning limitations, others, like University of Toronto economist Kevin A. Bryan, suggest that these limitations could stem from intentional training constraints. Bryan posits that if models are tasked to solve problems within tight time frames, they may resort to approximate solutions rather than exhaustive reasoning processes.
Critics of the Apple research, including software engineer Sean Goedecke, argue that models may choose not to attempt complex tasks like the Tower of Hanoi because they recognize the limitations of manual computation. Furthermore, independent AI researcher Simon Willison contends that the puzzles employed in the study may not accurately reflect the capabilities of LLMs, suggesting that failures could result from running out of tokens in the context window rather than inherent reasoning deficits.
While the Apple researchers caution against overgeneralizing their findings, they acknowledge that the puzzle environments represent a limited slice of reasoning tasks and may not capture the full range of real-world reasoning challenges. They also note that reasoning models demonstrate improvements in medium complexity scenarios and maintain utility in specific applications.
The credibility of claims surrounding AI reasoning models is not entirely diminished by these findings. Instead, the studies may indicate that the extended context reasoning methods employed by SR models are not the path to achieving general intelligence. This suggests that advancements in reasoning capabilities may necessitate fundamentally different approaches rather than merely refining current methodologies.
The results from Apple's study have sparked widespread debate within the AI community. Generative AI remains a contentious topic, with supporters and critics expressing polarized views on the technology's general utility. While proponents contest the study's conclusions, critics, including Gary Marcus, argue that the findings reinforce the notion that these systems rely heavily on pattern-matching rather than true systematic reasoning.
Despite the challenges highlighted in these studies, it is essential to recognize that even sophisticated pattern-matching models can be valuable tools for users, provided that their limitations are understood. As Marcus points out, LLMs will continue to be beneficial for tasks like coding, brainstorming, and writing in the near future.